本文以adxp-agent节点为例,演示如何基于rhcs创建高可用的服务。假设读者已经搭建好rhcs环境。
配置高可用集群:
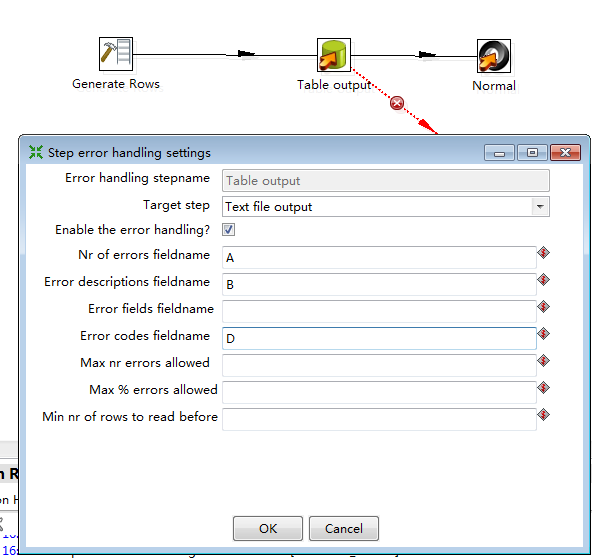
打开luci登录界面, 点击create, 创建集群
在下面的五个选项中,“Download packages”表示在线下载并自动安装RHCS软件包,而“Use locally installed packages”表示用本地安装包进行安装。大多数情况下,RHCS组件包在集群搭建时已经手动安装完成,所以这里选择本地安装。
剩下两个复选框分别是启用共享存储支持(Enable Shared Storage Support)、节点加入集群时重启系统(Reboot nodes before joining cluster)这些创建cluster的设置,可选可不选,这里不做任何选择。
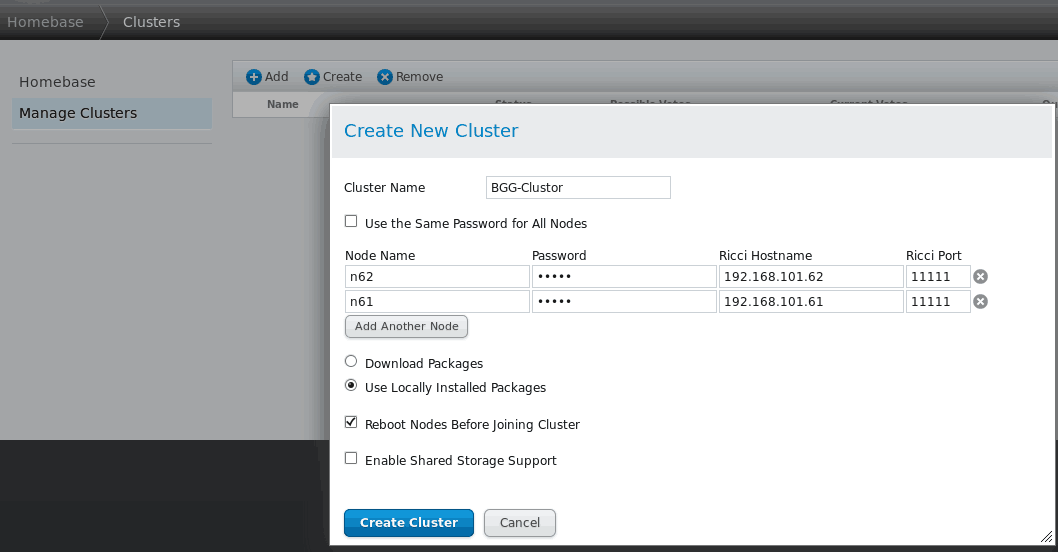
点击create cluster按钮完成集群配置。若创建成功,下图可以浏览集群各节点状态
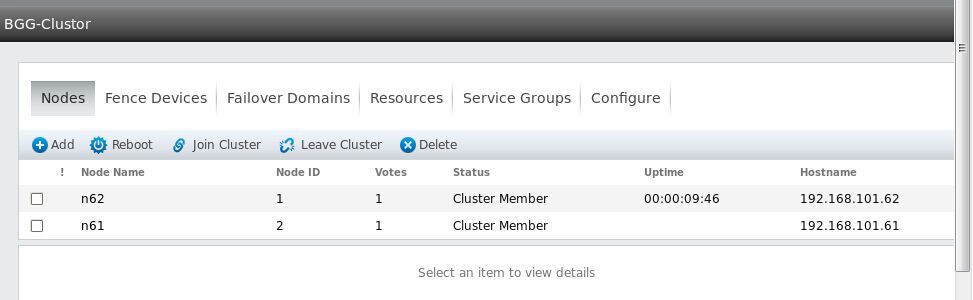
进入Fence Devices页签创建 fence 设备,此处为了演示随意建一个。实际生产环境中,必须使用 fence 硬件设备。(这里根据客户的具体情况决定)
以上属于rhcs平台搭建环节,故简述。
Failover Domain是配置集群的失败转移域,通过失败转移域可以将服务和资源的切换限制在指定的节点间。
比如可以指定a001, a002, a003三台机器作为mysql的失败转移域。部署后若某台节点上的mysql出现不可用,就会在这几个节点之间切换。下面具体说明:
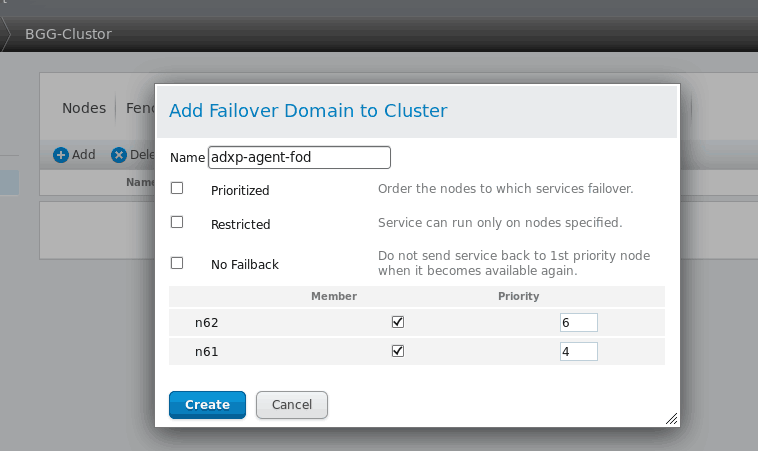
下图操作将创建adxp服务的失败转移域,其参数如下:
? Name:创建的失败转移域名称,起一个易记的名字即可。
? Prioritized:是否在Failover domain 中启用域成员优先级设置,这里选择启用。
? Restricted:表示是否在失败转移域成员中启用服务故障切换限制。
? No failback:表示在这个域中使用故障切回功能,也就是说,主节点故障时,备用节点会自动接管主节点服务和资源,当主节点恢复正常时,集群的服务和资源会从备用节点自动切换到主节点。(这里保持默认:不回切)
然后,在Member复选框中,选择加入此域的节点,这里选择的是n62和n61节点,然后在“priority”处设置优先级。越小优先级越高。
所有设置完成,点击Submit按钮。
Resources是集群的核心,主要包含服务脚本、IP地址、文件系统等
- 对于adxp-monitor, 只需配置一项Resource即可,即monitor自身
- 对于adxp-agent节点,需要添加agent运行过程中所需的所有服务(共三项,分别为h2数据库,aetl-server与adxp-agent应用)
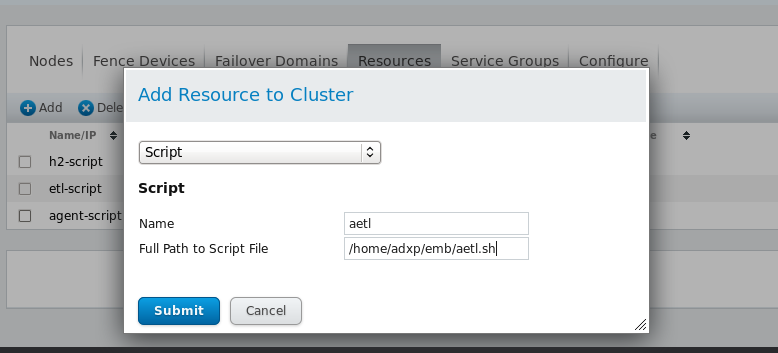
下图演示创建adxp-agent节点所需的三项Resource。首先是添加aetl资源的配置界面,其参数如下:
? Name:Resource名称
? Full Path to Script File:指向对应脚本的绝对路径,脚本已附带在产品包之中。(各个节点要将产品包部署到同一位置)
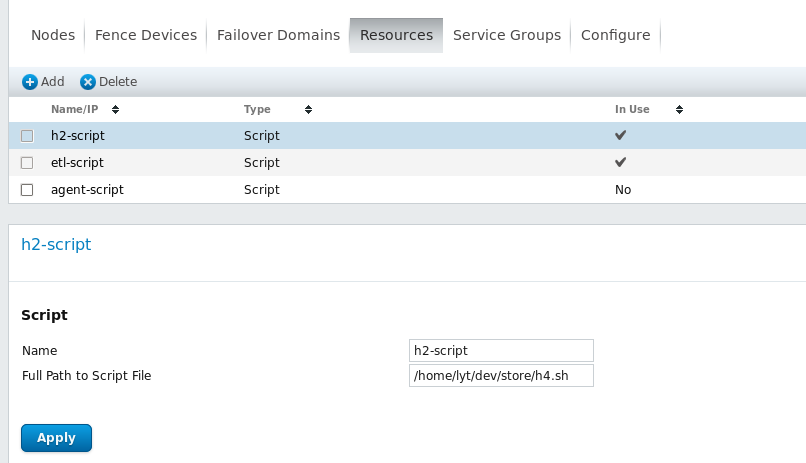
除aetl之外,继续向集群中添加adxp-agent所需的h2与agent资源,如下图:
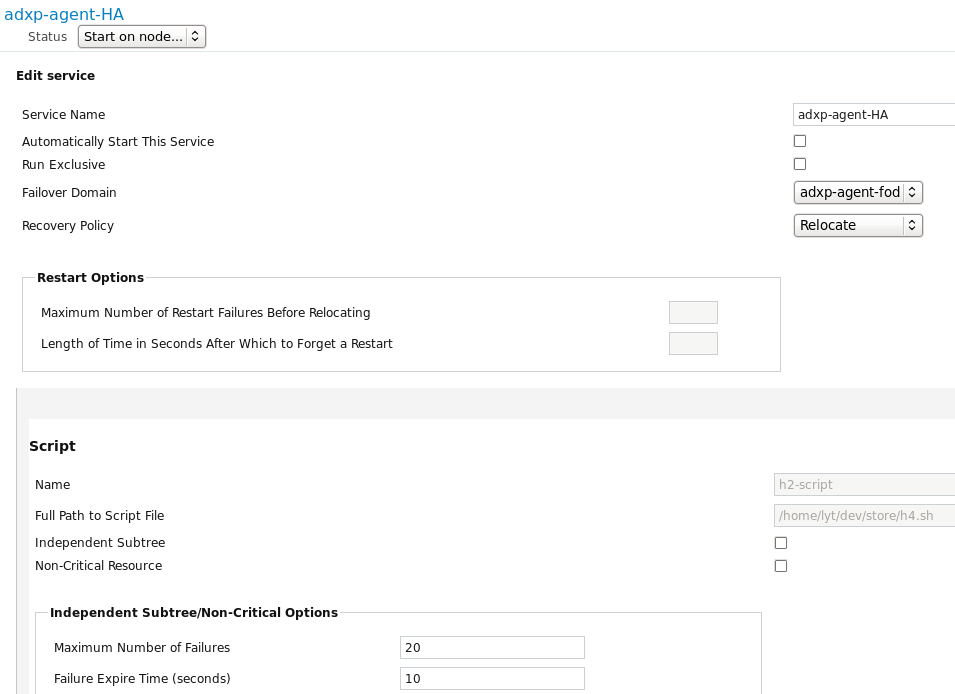
最后也是最终的一步,添加服务组:
新建服务组,引入刚才新建的三个资源(agent, etl, h2)在一个服务组内,可通过添加一个resource(包含两个child resource)的方式。
主要配置项如下:
? Service Name:服务组名称,起一个易记的名字即可。
? Failover Domain:失败转移域,服务与资源将在此域中的节点切换。
? Recovery Policy: 恢复策略,主要有重启(原节点restart尝试)与重分配(切换节点)
所有服务添加完成后,如果应用程序设置正确,服务将自动启动。在Service Groups中可以看到服务组的启动状态,正常情况下,会显示当前服务运行所在节点。
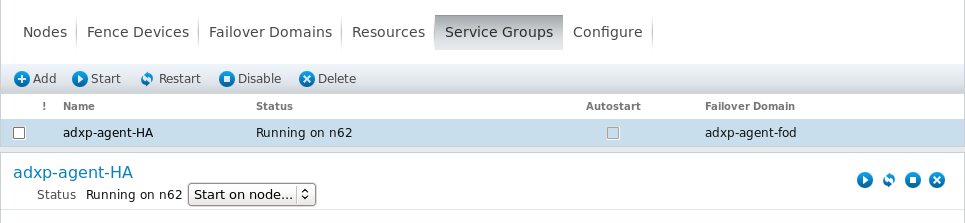
高可用性验证测试:
- 部署完成后在一个节点A
- 登录A节点机器,通过脚本对某服务运行stop命令或者直接kill pid
- 观察luci是否能重新拉起应用(restart或relocate到另一机器上)
- 另外留意:同一个服务组内,一个应用/服务的挂掉会触发组内所有应用/服务的Recovery行为